
Tweet Scraping with Tweepy: Search X/Twitter Posts Using API v2, pandas, and CSV Export
Collecting public posts from Twitter, now called X, can be useful for data science projects such as sentiment analysis, trend analysis, topic monitoring, and social media research.
In the original version of this blog, we used Tweepy with Twitter API v1.1 and api.search_tweets. That approach was common in 2022.
Today, the safer and more modern way is to use:
- X Developer account
- X API v2
- Tweepy
Client - bearer token
- environment variables
- pagination
- pandas DataFrame
- CSV export
In this tutorial, we will update the old workflow and collect public posts using Tweepy and the X API v2.
I will still use the word “tweet” in some places because many developers still search for “tweet scraping with Tweepy”, but the platform now uses “posts”.
Important Note About Access
X/Twitter API access has changed a lot since 2022. Some endpoints, limits, and pricing depend on your developer access level and current plan.
So, before running the code, check:
- whether your developer account is active
- whether your app has access to the endpoint
- whether your plan allows recent search
- whether you have enough monthly or daily quota
- whether your use case follows X Developer Policy
Do not scrape private content, bypass login walls, collect sensitive personal data unnecessarily, or use this data for spam.
What This Tutorial Covers
We will cover:
- creating a developer app
- getting API credentials
- storing credentials safely
- installing Tweepy
- using
tweepy.Client - searching recent public posts
- paginating results
- extracting post and user metadata
- saving results as CSV
- loading results into pandas
- common problems and fixes
- what to do next with the collected data
Getting API Keys
First, you need an X Developer account.
Go to the developer portal and create a project/app. Then save the credentials.
You may see keys such as:
- API Key
- API Key Secret
- Bearer Token
- Access Token
- Access Token Secret
For recent search with API v2, the simplest setup usually uses the Bearer Token.
Developer app setup screenshot:
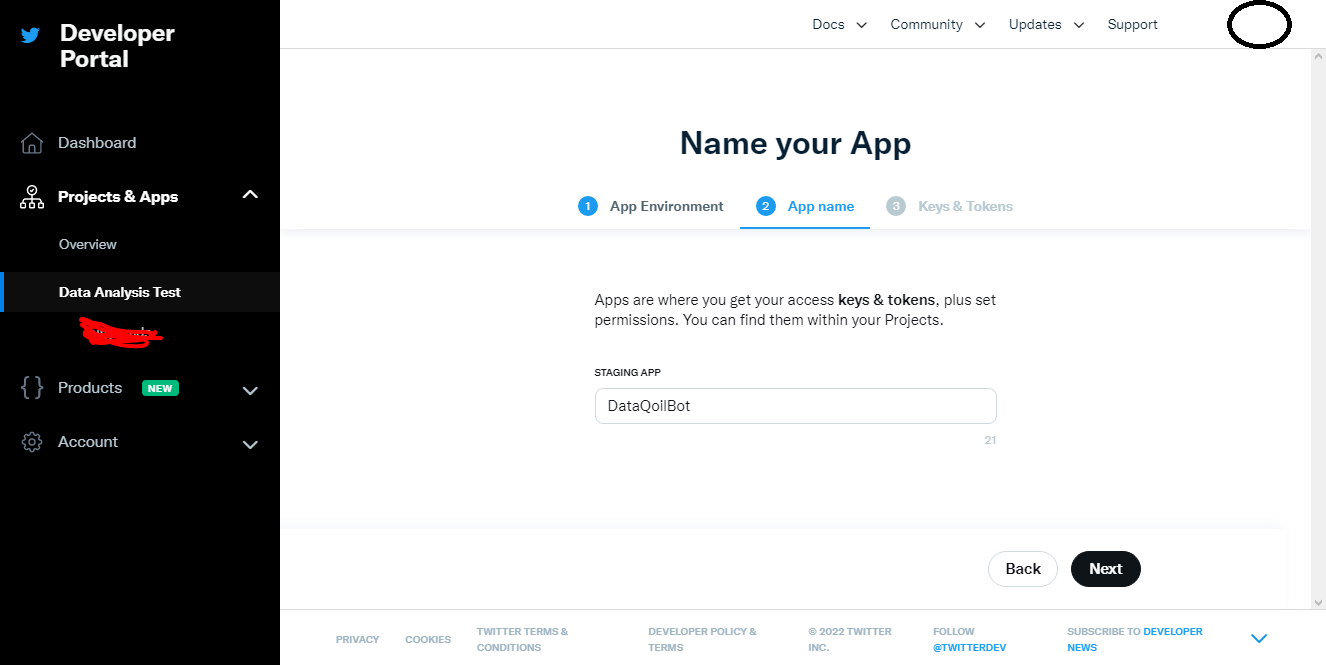
API key screenshot:
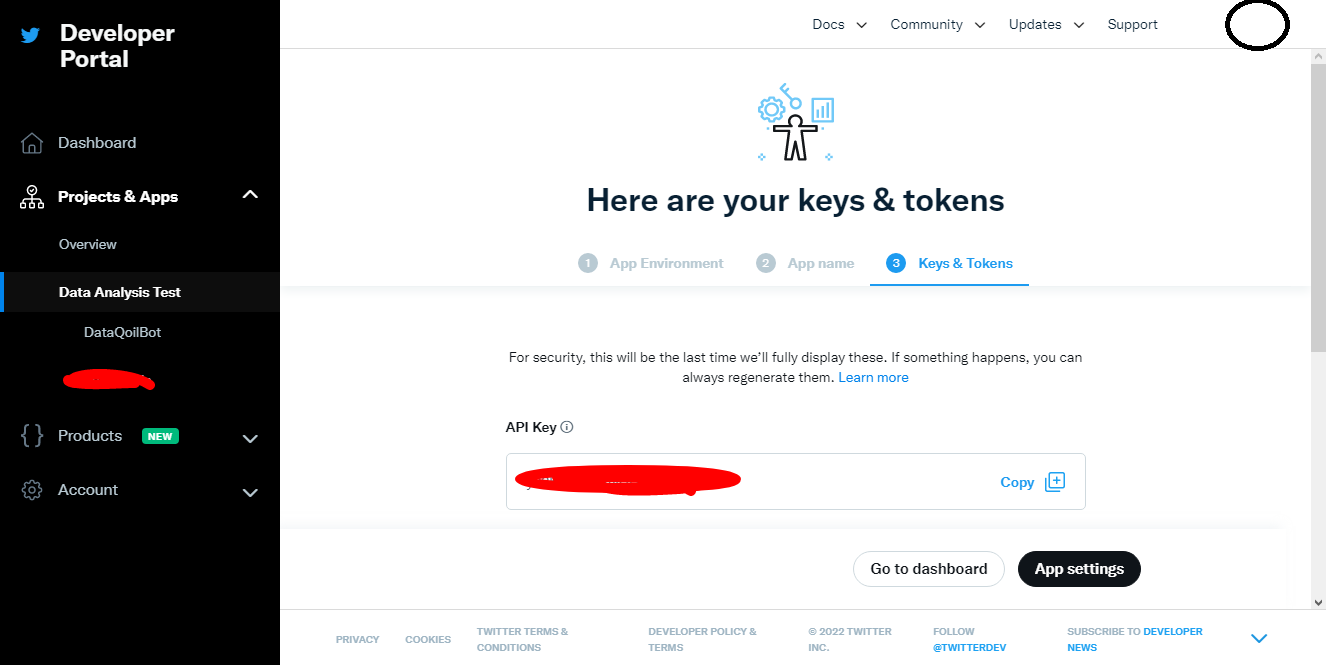
Do not share these keys publicly.
Store API Keys Safely
Do not write API keys directly in the code.
Bad:
bearer_token = "my-real-token"
Better:
bearer_token = os.environ["X_BEARER_TOKEN"]
Create a .env file:
X_BEARER_TOKEN=your_bearer_token_here
Add .env to .gitignore:
.env
__pycache__/
*.pyc
*.csv
Install python-dotenv:
pip install python-dotenv
Now your code can load the token safely.
Install Tweepy
Install Tweepy from PyPI:
pip install tweepy pandas python-dotenv
The original post installed Tweepy from GitHub:
pip install git+https://github.com/tweepy/tweepy.git
That can be useful when testing development versions, but for a normal project, PyPI is simpler and more stable.
Import Libraries
import os
from pathlib import Path
import pandas as pd
import tweepy
from dotenv import load_dotenv
Load the environment variables:
load_dotenv()
BEARER_TOKEN = os.environ["X_BEARER_TOKEN"]
Create Tweepy Client
With X API v2, use tweepy.Client.
client = tweepy.Client(
bearer_token=BEARER_TOKEN,
wait_on_rate_limit=True
)
The wait_on_rate_limit=True option tells Tweepy to wait automatically when the rate limit is reached.
Legacy v1.1 Code
The old version of this blog used OAuth 1.0a and API v1.1.
import tweepy as tw
auth = tw.OAuthHandler(api_key, api_secret)
auth.set_access_token(access_token, access_token_secret)
api = tw.API(
auth,
wait_on_rate_limit=True
)
Then it used:
tw.Cursor(
api.search_tweets,
q=key_word,
count=max_items
).items(max_items)
This was common in older tutorials. For new projects, prefer the API v2 client shown above.
Make First Search API Call
Let us search recent public posts about a topic.
query = "climate lang:en -is:retweet"
response = client.search_recent_tweets(
query=query,
max_results=10,
tweet_fields=[
"id",
"text",
"created_at",
"lang",
"public_metrics",
"source",
]
)
for tweet in response.data or []:
print(tweet.id, tweet.text[:100])
The query means:
climate: search keywordlang:en: English posts-is:retweet: exclude retweets/reposts
This gives a cleaner dataset for text analysis.
About Recent Search
Recent search returns posts from the recent search window supported by your API access. It is good for small data science experiments, dashboards, and topic monitoring.
If you need older historical data, you may need a different endpoint, access level, or product.
Useful Query Operators
Examples:
climate lang:en -is:retweet
"machine learning" lang:en -is:retweet
python OR pandas lang:en -is:retweet
#datascience lang:en -is:retweet
from:openai
to:openai
url:github.com
has:links
has:media
Good queries make the collected data much cleaner.
Collect Posts with Pagination
One API call usually returns only a limited number of posts. To collect more, use pagination.
Tweepy provides Paginator.
def search_posts(
client,
query,
max_posts=100,
max_results_per_page=100,
):
"""Search recent public posts using X API v2 and Tweepy."""
posts = []
paginator = tweepy.Paginator(
client.search_recent_tweets,
query=query,
max_results=max_results_per_page,
tweet_fields=[
"id",
"text",
"created_at",
"lang",
"public_metrics",
"source",
"conversation_id",
"possibly_sensitive",
"entities",
],
user_fields=[
"id",
"username",
"name",
"created_at",
"description",
"location",
"verified",
"public_metrics",
],
expansions=[
"author_id",
],
)
for response in paginator:
if response.data is None:
continue
users = {}
if response.includes and "users" in response.includes:
users = {
user.id: user
for user in response.includes["users"]
}
for tweet in response.data:
user = users.get(tweet.author_id)
public_metrics = tweet.public_metrics or {}
user_metrics = user.public_metrics if user else {}
row = {
"tweet_id": tweet.id,
"tweet_created_at": tweet.created_at,
"text": tweet.text,
"lang": tweet.lang,
"source": tweet.source,
"conversation_id": tweet.conversation_id,
"possibly_sensitive": tweet.possibly_sensitive,
"retweet_count": public_metrics.get("retweet_count"),
"reply_count": public_metrics.get("reply_count"),
"like_count": public_metrics.get("like_count"),
"quote_count": public_metrics.get("quote_count"),
"author_id": tweet.author_id,
"username": user.username if user else None,
"name": user.name if user else None,
"user_created_at": user.created_at if user else None,
"user_description": user.description if user else None,
"user_location": user.location if user else None,
"user_verified": user.verified if user else None,
"user_followers_count": user_metrics.get("followers_count") if user else None,
"user_following_count": user_metrics.get("following_count") if user else None,
"user_tweet_count": user_metrics.get("tweet_count") if user else None,
"query": query,
}
posts.append(row)
if len(posts) >= max_posts:
return pd.DataFrame(posts)
return pd.DataFrame(posts)
Use it:
df = search_posts(
client=client,
query="climate lang:en -is:retweet",
max_posts=100
)
df.head()
Save Posts to CSV
output_dir = Path("data")
output_dir.mkdir(exist_ok=True)
output_path = output_dir / "x_posts_climate.csv"
df.to_csv(
output_path,
index=False,
encoding="utf-8"
)
print(f"Saved {len(df)} rows to {output_path}")
Read it later:
df = pd.read_csv(
"data/x_posts_climate.csv",
parse_dates=["tweet_created_at", "user_created_at"]
)
Search Multiple Keywords
The original function accepted multiple keywords. We can keep the same idea.
def search_multiple_topics(
client,
keywords,
language="en",
posts_per_keyword=100,
):
all_frames = []
for keyword in keywords:
query = f"{keyword} lang:{language} -is:retweet"
print(f"Searching query: {query}")
topic_df = search_posts(
client=client,
query=query,
max_posts=posts_per_keyword
)
topic_df["keyword"] = keyword
all_frames.append(topic_df)
if not all_frames:
return pd.DataFrame()
return pd.concat(
all_frames,
ignore_index=True
)
Use it:
keywords = [
"climate",
"funny",
]
tweets_df = search_multiple_topics(
client=client,
keywords=keywords,
language="en",
posts_per_keyword=50
)
tweets_df.head()
Save:
tweets_df.to_csv(
"data/x_posts_multiple_topics.csv",
index=False,
encoding="utf-8"
)
Extract Hashtags
If you request entities, some posts may include hashtags.
def extract_hashtags(entities):
if not isinstance(entities, dict):
return []
hashtags = entities.get("hashtags", [])
return [
item.get("tag")
for item in hashtags
if item.get("tag")
]
If the entities column is stored as a dictionary in memory:
df["hashtags"] = df["entities"].apply(extract_hashtags)
If you save and reload CSV, dictionaries may become strings. In that case, store hashtags separately during collection if you need them.
Safer Minimal Data Collection
The old version collected many user fields. For many analysis tasks, you do not need all of them.
A safer minimal dataset can include:
- post ID
- post text
- created date
- language
- public metrics
- query keyword
Avoid collecting unnecessary personal profile fields unless you have a clear reason.
Example minimal row:
row = {
"tweet_id": tweet.id,
"tweet_created_at": tweet.created_at,
"text": tweet.text,
"lang": tweet.lang,
"like_count": public_metrics.get("like_count"),
"retweet_count": public_metrics.get("retweet_count"),
"reply_count": public_metrics.get("reply_count"),
"quote_count": public_metrics.get("quote_count"),
"query": query,
}
This is better for privacy and easier for text analysis.
Complete Script
Here is a complete beginner-friendly script.
import os
from pathlib import Path
import pandas as pd
import tweepy
from dotenv import load_dotenv
load_dotenv()
BEARER_TOKEN = os.environ["X_BEARER_TOKEN"]
def create_client():
return tweepy.Client(
bearer_token=BEARER_TOKEN,
wait_on_rate_limit=True
)
def search_posts(
client,
query,
max_posts=100,
max_results_per_page=100,
):
posts = []
paginator = tweepy.Paginator(
client.search_recent_tweets,
query=query,
max_results=max_results_per_page,
tweet_fields=[
"id",
"text",
"created_at",
"lang",
"public_metrics",
"source",
"conversation_id",
"possibly_sensitive",
"entities",
],
user_fields=[
"id",
"username",
"name",
"created_at",
"description",
"location",
"verified",
"public_metrics",
],
expansions=[
"author_id",
],
)
for response in paginator:
if response.data is None:
continue
users = {}
if response.includes and "users" in response.includes:
users = {
user.id: user
for user in response.includes["users"]
}
for tweet in response.data:
user = users.get(tweet.author_id)
public_metrics = tweet.public_metrics or {}
user_metrics = user.public_metrics if user else {}
posts.append({
"tweet_id": tweet.id,
"tweet_created_at": tweet.created_at,
"text": tweet.text,
"lang": tweet.lang,
"source": tweet.source,
"conversation_id": tweet.conversation_id,
"possibly_sensitive": tweet.possibly_sensitive,
"retweet_count": public_metrics.get("retweet_count"),
"reply_count": public_metrics.get("reply_count"),
"like_count": public_metrics.get("like_count"),
"quote_count": public_metrics.get("quote_count"),
"author_id": tweet.author_id,
"username": user.username if user else None,
"name": user.name if user else None,
"user_created_at": user.created_at if user else None,
"user_description": user.description if user else None,
"user_location": user.location if user else None,
"user_verified": user.verified if user else None,
"user_followers_count": user_metrics.get("followers_count") if user else None,
"user_following_count": user_metrics.get("following_count") if user else None,
"user_tweet_count": user_metrics.get("tweet_count") if user else None,
"query": query,
})
if len(posts) >= max_posts:
return pd.DataFrame(posts)
return pd.DataFrame(posts)
def search_multiple_topics(
client,
keywords,
language="en",
posts_per_keyword=100,
):
all_frames = []
for keyword in keywords:
query = f"{keyword} lang:{language} -is:retweet"
print(f"Searching query: {query}")
topic_df = search_posts(
client=client,
query=query,
max_posts=posts_per_keyword
)
topic_df["keyword"] = keyword
all_frames.append(topic_df)
if not all_frames:
return pd.DataFrame()
return pd.concat(
all_frames,
ignore_index=True
)
def main():
client = create_client()
keywords = [
"climate",
"funny",
]
df = search_multiple_topics(
client=client,
keywords=keywords,
language="en",
posts_per_keyword=50
)
output_dir = Path("data")
output_dir.mkdir(exist_ok=True)
output_path = output_dir / "x_posts.csv"
df.to_csv(
output_path,
index=False,
encoding="utf-8"
)
print(df.head())
print(f"Saved {len(df)} posts to {output_path}")
if __name__ == "__main__":
main()
Simple EDA After Collection
After saving posts, you can do a quick EDA.
df = pd.read_csv(
"data/x_posts.csv",
parse_dates=["tweet_created_at", "user_created_at"]
)
df.shape
Check languages:
df["lang"].value_counts()
Top keywords:
df["keyword"].value_counts()
Most liked posts:
df.sort_values(
"like_count",
ascending=False
)[["tweet_created_at", "username", "text", "like_count"]].head()
Posts over time:
df.set_index("tweet_created_at").resample("H").size().plot()
Text Cleaning for Sentiment Analysis
For sentiment analysis, clean text first.
import re
def clean_text(text):
text = str(text)
text = re.sub(r"http\S+", "", text)
text = re.sub(r"@\w+", "", text)
text = re.sub(r"#", "", text)
text = re.sub(r"\s+", " ", text)
return text.strip()
df["clean_text"] = df["text"].apply(clean_text)
Now the text is easier to use for:
- sentiment analysis
- topic modelling
- word clouds
- keyword extraction
- text classification
Common Problems and Fixes
Problem 1: 401 Unauthorized
Check:
- bearer token is correct
.envis loaded- token has not been revoked
- app is active
Problem 2: 403 Forbidden
Possible reasons:
- endpoint is not available in your access level
- app permissions are not correct
- query requires access you do not have
- project/app setup is incomplete
Problem 3: 429 Too Many Requests
You hit a rate limit.
Fixes:
- use
wait_on_rate_limit=True - reduce
max_posts - reduce request frequency
- collect data in smaller batches
- check your current plan limits
Problem 4: No Data Returned
Possible reasons:
- query is too narrow
- language filter removes all results
- endpoint access is limited
- there are no recent posts for that query
-is:retweetremoves too many results
Try a broader query:
climate lang:en
Problem 5: CSV Encoding Issue
Use:
encoding="utf-8"
when saving and reading files.
Ethical Data Use
When collecting social media data, follow these rules:
- collect only what you need
- respect API terms and rate limits
- do not collect private data
- do not bypass protections
- do not use data for spam
- avoid exposing personal information in public reports
- aggregate results when possible
- be careful with sensitive topics
- delete data when it is no longer needed
Public does not always mean harmless. Use the data responsibly.
What Next?
After collecting posts, you can try:
- exploratory data analysis
- sentiment analysis
- topic modelling
- hashtag analysis
- trend detection
- bot/spam filtering
- word clouds
- classification
- dashboarding with Streamlit
- storing posts in a database
For example, this data can be used for a small sentiment analysis project on topics such as climate, sports, movies, or technology.
Final Thoughts
In this tutorial, we updated the old tweet scraping workflow using Tweepy and the modern X API v2.
The main changes are:
- use
tweepy.Clientinstead of oldAPI.search_tweets - use a bearer token for recent search
- store credentials in environment variables
- use pagination for collecting more posts
- save clean results into a pandas DataFrame and CSV
- collect only the fields you actually need
Tweepy still makes it much easier to work with the X/Twitter API, but access rules, endpoints, and limits can change. Always check the current X Developer documentation before building a real project.




Comments