
Crowd Counting Made Easy
Contents
Experience Of Being Udacity Scholar:
As a scholar of Udacity’s Secure and Private AI Challenge course by Facebook, I have not only learned about the Pytorch and Pysyft from scratch but I also learned how it feels to be a Udacity scholar. First of all, the Slack channel is awesome and everyone is eager to learn and help each other. I was engaged in multiple study groups and every group has very helpful members and I learned how to work in groups and contribute on projects. I would like to give huge thanks to Udacity and all the Slack members for this wonderful opportunity. While attending this course, I also started the popular trend of programming #100DaysOfCode. And I have created an entire GitHub repository of this. Here is a link.
Crowd Counting Made Easy
The problem of crowd counting has been studied for research purposes for quite some time. For too long, countless precious lives have been lost in stampedes. In countries with huge festivals, crowd management is a serious issue. One popular festival is ‘Kumbh Mela’, in India. It may be almost impossible to control the crowds in such scenarios, but the respective authorities can always take precautionary controls before risk occurs. Human beings do not have the ability to count people in crowds, but we can make intelligent machines and programs that can do it easily. Artificial Intelligence can achieve this easily. There is nothing like magic in the field of AI, but we have various algorithms and approaches which solve our problems mathematically. The most important thing we need to create a crowd estimation system is data- a good dataset with proper information always helps developers to create a model. Another important thing is the choice of mode. We have various models which provide different levels of accuracy for different datasets. We will cover some of the best approaches here.
Contents:
- Prerequisites
- Datasets
- Previous Achievement History
- Best Models
- Useful Links
Prerequisites
The requirements for understanding this blog are not high. A beginner to AI/ ML can easily understand the contents inside this article.
Datasets
Crowd Counting has traditionally been employed on several classic datasets. Many of these are publicly available on the web.
- INRIA Person datasets
- Mall Dataset
- Caltech Pedestrian Dataset
- ShanghaiTech Dataset
- World Expo Dataset
- Grand Central Station Dataset
- UCF CC 50
- UCF-QNRF — A Large Crowd Counting Data Set
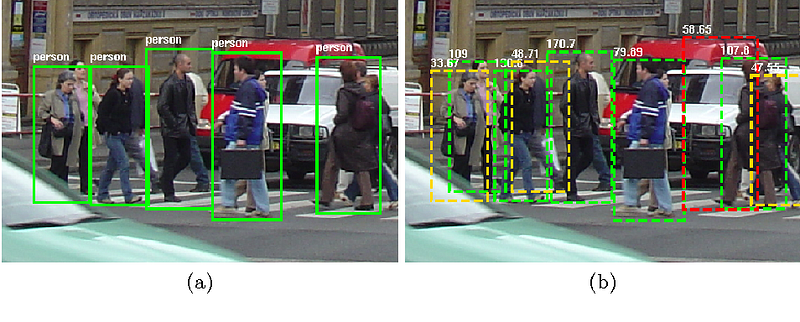
* INRIA Person datasets:
- Includes large set of marked up images of standing or walking people.
- The dataset is divided in two formats:
a. original images with corresponding annotation files, and
b. positive images in normalized 64x128 pixel format (as used in the CVPR paper) with original negative images.
Annotations are the bounding box( a rectangular box around the detected object) with the corresponding class label. Normalization of image is done in order to get proper histogram of image. During Computer Vision problems, images are generally normalized in the range of (0, 1) by doing this the error/ loss can be decreased rapidly hence faster convergence of the model. But in general we can transform the image into the desired range.
Sample from the dataset is given below:
* Mall Datasets:
- Composed by RGB images of frames in a video (as inputs) and the object counting on every frame, this is the number of pedestrians (object) in the image
- Images are 480x640 pixels at 3 channels of the same spot recorded by a webcam in a mall, but there is a different number of persons on every frame, which is a problem in crowd counting.
- This dataset can be used for regression.
- The properties of the dataset are:
- Video length: 2000 frames
- Frame size: 640x480
- Frame rate: < 2 Hz
- In dataset, over 60,000 pedestrians were labeled in 2000 video frames.

Example frame
* Caltech Pedestrian Datasets:
- Consists of approximately 10 hours of 640x480 30Hz video taken from a vehicle driving through regular traffic in an urban environment.
- About 250,000 frames (in 137 approximately minute long segments) with a total of 350,000 bounding boxes and 2300 unique pedestrians were annotated.
- Annotation includes temporal correspondence between bounding boxes and detailed occlusion labels.
Occlusion on the field of Computer Vision is the condition when the object we’re tracking is hidden by scene or other objects.
For more information please follow the link.

Sample example
* Shanghai Tech Dataset:
- Appeared in CVPR 2016 paper Single Image Crowd Counting via Multi Column Convolutional Neural Network.
- Authors of the dataset have made two parts Part A and Part B.
- Both datasets have unique data images.
- In each dataset , there are 3 folders:
- images: the jpg image file
- ground-truth: matlab file contain annotated head (coordinate x, y)
- ground-truth-h5: people density map
Ground truth in the field of Computer Vision is the location of the object the model will predict if it is working fine. In general we can use it to compare with the result of model.
* World Expo Dataset:
- Split into two parts
- 1,127 one-minute long video sequences out of 103 scenes are treated as training and validation sets.
- 3 labeled frames in each training video and the interval between two labeled frames is 15 seconds.

* Grand Central Station Dataset:
Description:
- Length: 33:20 minutes
- Frame No.: 50010 frames
- Frame Rate: 25fps, 720x480
It includes 3 files:
- [Video] contains the video compressed into 1.1 GB AVI file by ffmpeg for download convenience.
- [Trajectories] contains the KLT keypoint trajectories extracted from the video, which are used in our CVPR2012 paper.
- [TrajectoriesNew] contains new bunch of KLT keypoint trajectories extracted from the video with KLT tracker slightly modified.

* UCF CC 50 Dataset:
- Contains images of extremely dense crowds.
- The images are collected mainly from the FLICKR.
- This dataset was used on Multi-Source Multi-Scale Counting in Extremely Dense Crowd Images.

* UCF-QNRF — A Large Crowd Counting Data Set:
- Contains 1535 images which are divided into train and test sets of 1201 and 334 images respectively.
- According to authors, this dataset is most suitable for training very deep Convolutional Neural Networks (CNNs) since it contains order of magnitude more annotated humans in dense crowd scenes than any other available crowd counting dataset.
- Authors have even provided the comparison of dataset with other dataset.
- This dataset was used on Composition Loss for Counting, Density Map Estimation and Localization in Dense Crowds.

Previous Achievement History
There have been various implementations to estimate the number of people in crowds but there always will be many challenges and limitations on the developed model. Some key challenges:
- One of the main challenges is the quality of the image/video. Taking higher resolution of image always helps to gain greater information but in dark side it requires lots of resources.
- Detecting the relative distance between any two people from a live visual is a tough task(a key measure that would be really useful to help measure density)
Best Models
* C³ Framework (Crowd Counting Code)
- A lot of research has been done on the field of object tracking/ object counting, but as time moves on, newer and faster techniques come along with new problems and solutions. Most of the research has been done for specific datasets only. But currently we have C³ Framework
- This framework works with 6 main datasets UCF CC 50, WorldExpo’10, SHT A, SHT B, UCF-QNRF, and GCC.
- Authors have used various models(AlexNet, VGG Series, ResNet Series etc.) for doing classification.
- MAE(Mean Absolute Error) and MSE(Mean Squared Error) are used for error calculation.
- And this model have relatively low MAE and MSE than other. Pytorch code of C³ Framework can be found on this GitHub link.
* CSRNet : Dilated Convolutional Neural Networks for Understanding the Highly Congested Scenes
- According to authors,
- “We propose a network for Congested Scene Recognition called CSRNet to provide a data-driven and deep learning method that can understand highly congested scenes and perform accurate count estimation as well as present high-quality density maps.
- The proposed CSRNet is composed of two major components: a convolutional neural network (CNN) as the front-end for 2D feature extraction and a dilated CNN for the back-end, which uses dilated kernels to deliver larger reception fields and to replace pooling operations.
- CSRNet is an easy-trained model because of its pure convolutional structure. We demonstrate CSRNet on four datasets (ShanghaiTech dataset, the UCF_CC_50 dataset, the WorldEXPO’10 dataset, and the UCSD dataset) and we deliver the state-of-the-art performance.
- In the ShanghaiTech Part_B dataset, CSRNet achieves 47.3% lower Mean Absolute Error (MAE) than the previous state-of-the-art method.
- We extend the targeted applications for counting other objects, such as the vehicle in TRANCOS dataset.
- Results show that CSRNet significantly improves the output quality with 15.4% lower MAE than the previous state-of-the-art approach.”
- The paper is publicly available here.

Pytorch Code can be found on this GitHub Link.
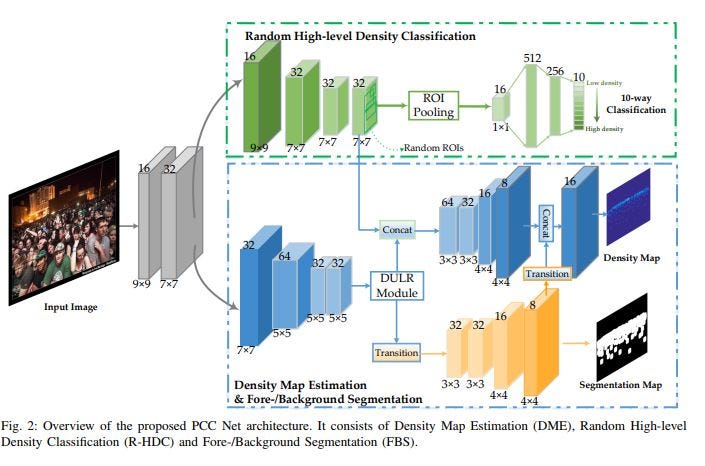
* PCC Net: Perspective Crowd Counting via Spatial Convolutional Network
This is another CNN based crowd counting technique by generating density. According to authors, It consists of:
- Density Map Estimation (DME) focuses on learning very local features for density map estimation;
- Random High-level Density Classification (R-HDC) extracts global features to predict the coarse density labels of random patches in images;
- Fore- /Background Segmentation (FBS) encodes mid-level features to segments the foreground and background

Pytorch code of PCCNet can be found on Github Link.
Conclusion
Now we have various algorithms and the frameworks to do crowd counting, we can choose any one of them and do experiments. There are still numerous research and frameworks not listed here but here is a link which have most of their links.
During writing this article I got lots of valuable suggestions from study group members(#sg_wonder_vision) and especially Pooja Vinod who have helped me complete this. She have made this awesome website and she have included our implementations.
Useful Links




Comments
Post comment