TextBaker¶
Synthetic Text Dataset Generator for OCR Training
![]()
![]()
Example Outputs¶
| Basic | Transformed | Colored | Background | Texture | Full Pipeline |
|---|---|---|---|---|---|
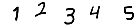 |
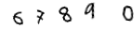 |
 |
 |
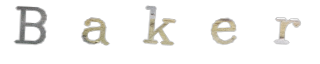 |
 |
📖 See Examples for code that generates these images.
Installation¶
From source:
Quick Start¶
GUI Application¶
CLI Generation¶
# Generate specific texts
textbaker generate "hello" "world" -d ./dataset
# Generate random samples with transforms
textbaker generate -n 100 --seed 42 -r "-15,15"
Python Library¶
from textbaker import TextGenerator, GeneratorConfig
generator = TextGenerator()
result = generator.generate("hello")
generator.save(result)
📖 See Examples for more detailed code samples.
Dataset Structure¶
Images are scanned recursively. Parent folder name = character label:
assets/dataset/
├── A/
│ └── sample1.png → label "A"
├── B/
│ └── sample1.png → label "B"
└── digits/
└── 0/
└── sample1.png → label "0"
Documentation¶
- Examples - Code samples with visual outputs
- Configuration - All config options explained
- CLI Reference - Command line usage
- API Reference - Python API documentation
Author¶
Ramkrishna Acharya — GitHub
License¶
MIT License — see LICENSE