Neural-Template-Matching
Template Matching Using Deep Learning
An experiment to do template matching based on neural networks.

Model Architecture
The model is a modified version of the original U-Net architecture. Instead of single encoder, two encoders (one for the query image and another for the original image) will be used. In original architecture, there are skip connections from encoder to decoder side. But here, the outputs from such blocks are first multiplied (or can be added i.e. encoding multiplication) and passed to the decoder. The inputs to the model will be, query image (where template will be at the center of a blank image) and input image (where that template is being searched). Both are of same size.
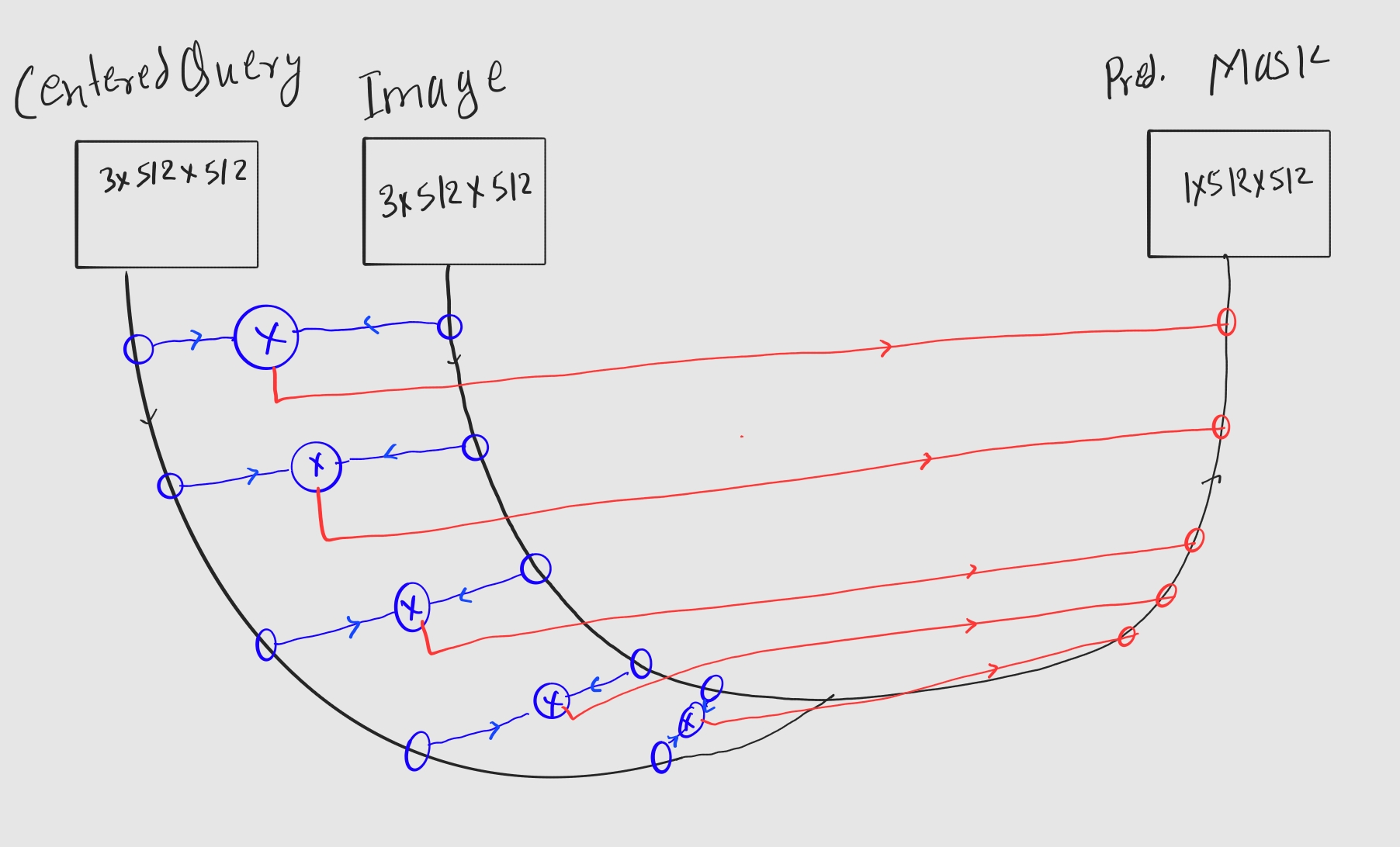 A basic architecture of a model.
A basic architecture of a model.
Training Procedure
Crop a part of an image based on the bounding box annotation available in COCO dataset. Then put that cropped part in the center of a blank image. Now the model’s input will be original image and that blank image. The target will be the mask where the cropped image originally was.
- Prepare a
.venvfile that contains following:
TRAIN_DIR=assets/training_data/train2017/train2017
TRAIN_ANNOTATION_DIR=assets/training_data/annotations_trainval2017/annotations/instances_train2017.json
VAL_DIR=assets/training_data/val2017/val2017
VAL_ANNOTATION_DIR=assets/training_data/annotations_trainval2017/annotations/instances_val2017.json
Had to do this to make it compatible with HPC. Slurm job is in scripts.
- A model is defined at temp_matching/model.py. By default, the encodings will be multiplied.
- A dataset handler is at temp_matching/data_handler.py. And the same config can be used for valid and train and with the use of fixed seed, the split is expected to be same everytime with same
train_size. - Trainer is at temp_matching/trainer.py.
Inference
A live_run.py should work out of the box. First compute the encodings of query and search based on that. Please download the weight files from Google Drive.
Results
Experiment: 2024-09-24
- Encoder:
ResNet152 - Train Data Per Epoch: 10000
- Valid Data Per Epoch: 500
- Batch Size: 32
- Image HW: 512, 512
- Optimizer: Adam with Lr=0.0001
- Loss function: DiceLoss
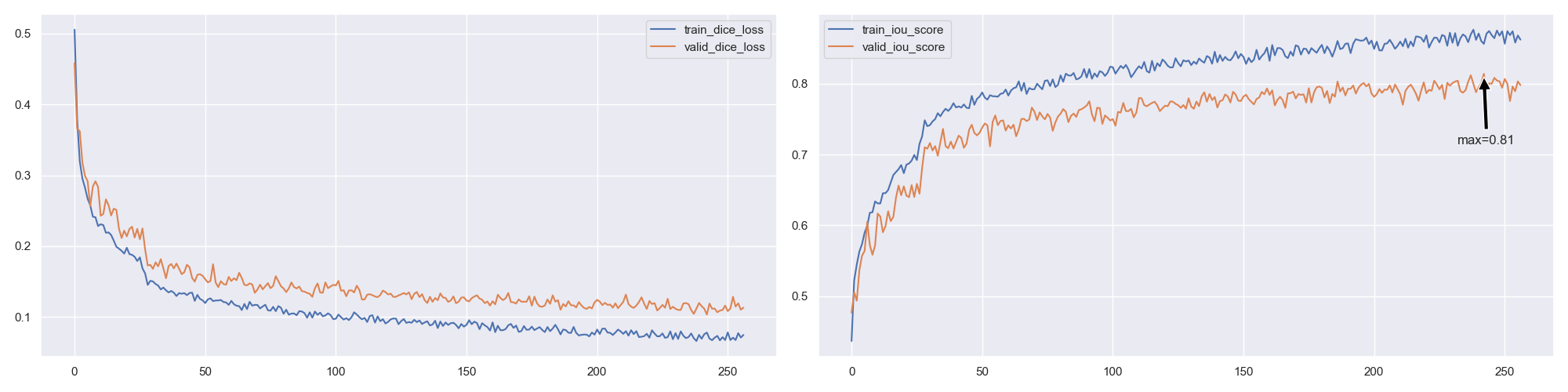
- Training Curve
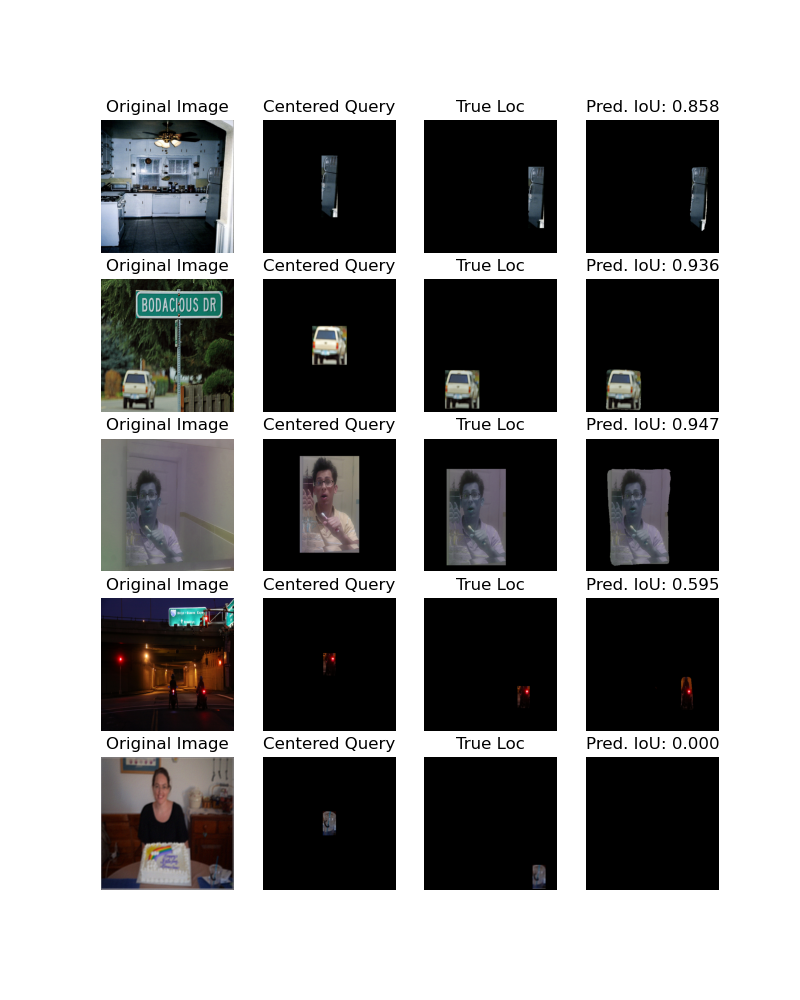
- Predictions at assets/2024-09-24/
- The weight file can be downloaded from Google Drive
- Some experiments I did are available on notebooks as well.
Demo on Unseen Scenes
Benchmarking with SIFT
Note that storing the mask was done to view masks later. I found RLE (Run Length Encoding to be the perfect for that task.)
The scripts to extract the masks and storing in RLE is temp_matching/benchmarking.py. And the plots are generated on the notebooks/test_benchmark.ipynb.
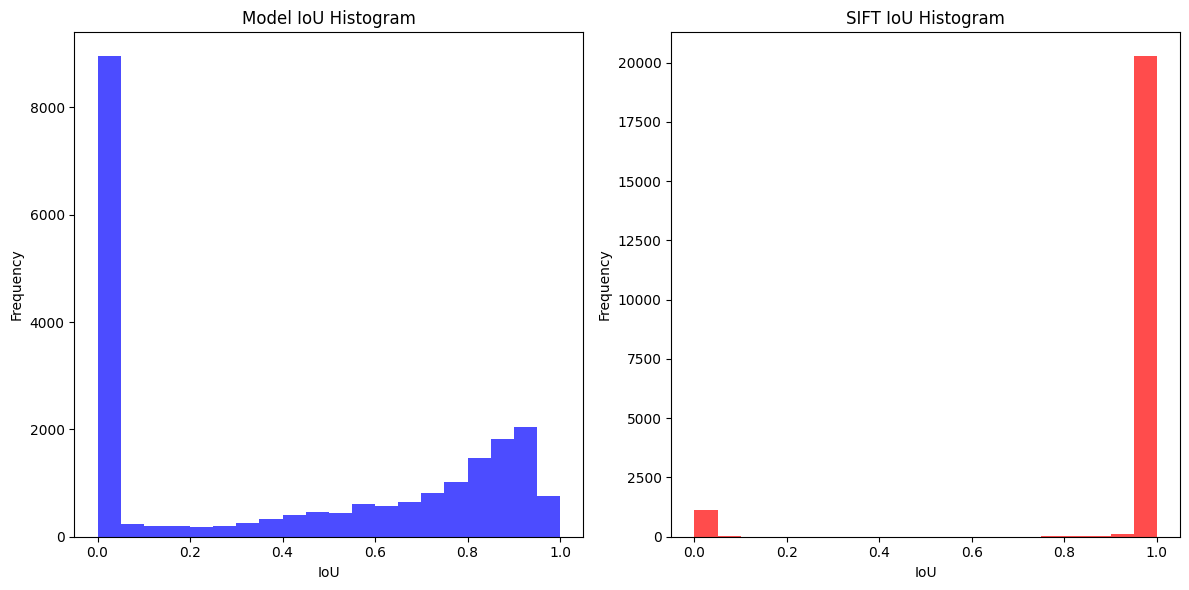
Above result shows that SIFT is far more better than the template matching model we trained. And after looking into the describe, it is even clearer.
| model_iou | sift_iou | model_time | sift_time | |
|---|---|---|---|---|
| count | 21627.000000 | 21627.000000 | 21627.000000 | 21627.000000 |
| mean | 0.415356 | 0.945153 | 0.020917 | 0.088319 |
| std | 0.391032 | 0.223428 | 0.112210 | 0.030342 |
| min | 0.000000 | 0.000000 | 0.000499 | 0.010363 |
| 25% | 0.000000 | 1.000000 | 0.000537 | 0.069422 |
| 50% | 0.432000 | 1.000000 | 0.000572 | 0.083969 |
| 75% | 0.825000 | 1.000000 | 0.000607 | 0.101738 |
| max | 1.000000 | 1.000000 | 1.225988 | 0.898370 |
Based on the IoU, SIFT seems to be outperforming the template matching model. However, it seems that model was faster than the SIFT. It must be because the model was tested on GPU while SIFT was not.
Where Model Outperformed SIFT
Out of 21627 only 232 cases.




Where SIFT outperformed Model
2057 cases. Some are as follows:




Where both failed
816 cases.



Conclusion
The results did not show that template matching with the model and the training I had is not better than the classical SIFT feature extractor. What could be the reasons?
- Training process is really sensitive. The input size, colorspace, rotation of template and the image, template size, minimizer function and so on.
- It is not trained with more variations of the images. For example, we want our model to be able to perform well in scale/rotation as well but it is not yet. However, we can use augmentation techniques during training for that.
I have trained several template matching models in other projects (very compact domain) and I have found them to better than SIFT only when I trained for weeks but still without much rotation/scale augmentation. In addition to that, I have also trained model with attention layers in different places of the architecture and still results were not great. This means it needs careful design of the architecture.
Citation
If you find this project helpful in your research or applications, please consider citing it as follows:
@misc{acharya2024template,
title={Template Matching Using Deep Learning},
author={Ramkrishna Acharya},
year={2024},
howpublished={\url{https://github.com/q-viper/template-matching}},
note={An experimental approach to template matching using dual-encoder U-Net architecture},
}
Alternatively, feel free to link to this repository.